本站文章除注明转载外,均为本站原创: 转载自love wife & love life —Roger 的Oracle技术博客
本文链接地址: Oracle Wallet 实施的一次悲惨经历
前几天一个运营商客户被某O记忽悠之后,准备上一个安全解决方案,其目的是为了
能够对rman备份文件进行加密处理。我们这里姑且不论rman 备份就可以进行加密。只讨论这里的wallet 实施方案。
当时的实施步骤如下(主库为4节点rac,dg备库是2节点rac):
1、停主库业务、停adg同步
2、主库创建wallet目录mkdir /u01/app/oracle/admin/crmdbn/wallet
3、配置主库grid用户的sqlnet.ora,添加如下内容:
ENCRYPTION_WALLET_LOCATION = (SOURCE =
(METHOD = FILE)
(METHOD_DATA =
(DIRECTORY =
/u01/app/oracle/admin/crmdbn/wallet)))
4、在主库设置安全码
alter system set encryption key identified by “Oracle_xxx”;
5、主库打开wallet
alter system set encryption wallet open identified by “Oracle_xxx”;
这里只在一个主库rac节点1执行了,其他几个节点并未执行;
6、在adg备库创建wallet
mkstore -wrl /u01/app/oracle/admin/crmdbns/wallet -create
7、在dg备库打开wallet
然后启动dg的时候,很显然会报错。实际上上述的操作步骤是有问题的;有如下几点操作不对:
1)如果主库是rac,wallet必须存放在共享磁盘上;否则在其中一个节点创建之前,就先将其他节点停掉,避免产生归档日志。
2)当主库rac其中一个节点创建好wallet之后,将wallet目录中的key scp拷贝到rac的其他节点对应wallet目录中。
当然,如果wallet存在共享磁盘上,也不需要这么麻烦了。
3)在dataguard备库上创建wallet根本就不需要操作,只需要创建对应的wallet目录(如果备库是rac,一样建议是共享目录来存放),然后将主库wallet master key 通过scp拷贝到备库wallet目录中(建议提前配置好备库监听的sqlnet.ora文件)。
4)备库启动wallet即可;另外对于wallet的创建,建议使用auto login 方式(直接创建wallet目录,并通过alter database 命令open wallet的方式,这并非自动打开wallet模式)。建议通过如下命令进行修改,将其修改为auto login方式(当然也可以使用owm图形界面来进行管理)
orapki wallet create -wallet /u01/app/oracle/admin/crmdbns/wallet -auto_login
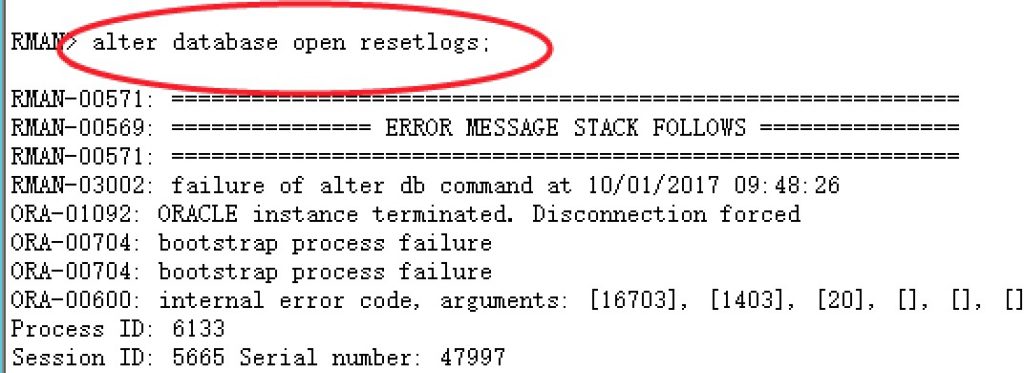
由于最开始的方案有问题,导致后面adg无法同步,启动mrp进程就报错,如下是错误:
Thu Jun 29 00:17:28 2017 Completed: alter database recover managed standby database using current logfile disconnect from session Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_28/thread_3_seq_31785.364.947825515 Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_28/thread_4_seq_29565.985.947825489 Force closing the keystore for standby rekey. Please re-copy the keystore from primary before re-open as needed. Apply redo for database master key re-key failed: new master key does not exist in the keystore Errors with log +ARCH/crmdbns/archivelog/2017_06_28/thread_4_seq_29565.985.947825489 MRP0: Background Media Recovery terminated with error 28374 Errors in file /u01/app/oracle/diag/rdbms/crmdbns/crmdbn1/trace/crmdbn1_pr00_107831.trc: ORA-28374: typed master key not found in wallet
我们可以看出,Oracle 在启动mrp进程时提示在备库的wallet中找不到对应的master key。在开始我并不明白,及时最开始mkstore 的操作是多余的,那么将主库的key文件scp到备库之后,不就完全一样了吗?为什么会提示找不到key呢?
而且我通过如下的方式对比了主库和备库的wallet内容信息,发现是匹配的,如下:
—node4 [oracle@crmdbn4 wallet]$ mkstore -wrl . -list Oracle Secret Store Tool : Version 11.2.0.4.0 - Production Copyright (c) 2004, 2013, Oracle and/or its affiliates. All rights reserved. Enter wallet password: Oracle Secret Store entries: ORACLE.SECURITY.DB.ENCRYPTION.Aa2psY/5bk9Sv4JEVRn29G0AAAAAAAAAAAAAAAAAAAAAAAAAAAAA ORACLE.SECURITY.DB.ENCRYPTION.MASTERKEY ORACLE.SECURITY.TS.ENCRYPTION.BS4mhLbiOqGrY3MfAQrWCsUCAwAAAAAAAAAAAAAAAAAAAAAAAAAA [oracle@crmdbn4 wallet]$ —adg1 [oracle@crm2dbn1 wallet]$ mkstore -wrl . -list Oracle Secret Store Tool : Version 11.2.0.4.0 - Production Copyright (c) 2004, 2013, Oracle and/or its affiliates. All rights reserved. Enter wallet password: Oracle_123 Oracle Secret Store entries: ORACLE.SECURITY.DB.ENCRYPTION.Aa2psY/5bk9Sv4JEVRn29G0AAAAAAAAAAAAAAAAAAAAAAAAAAAAA ORACLE.SECURITY.DB.ENCRYPTION.MASTERKEY ORACLE.SECURITY.TS.ENCRYPTION.BS4mhLbiOqGrY3MfAQrWCsUCAwAAAAAAAAAAAAAAAAAAAAAAAAAA [oracle@crm2dbn1 wallet]$
由此可见,上述这个报错应该另有隐情。我们需要进一步研究分析Oracle wallet打开之后,会做哪些事情。
www.killdb.com@startup
ORACLE instance started.
Total System Global Area 271400960 bytes
Fixed Size 2252424 bytes
Variable Size 167772536 bytes
Database Buffers 96468992 bytes
Redo Buffers 4907008 bytes
Database mounted.
Database opened.
www.killdb.com@ alter system set encryption key identified by "Oracle_123";
System altered.
www.killdb.com@select * from v$encryption_wallet;
WRL_TYPE
--------------------
WRL_PARAMETER
------------------------------------------------------------------
STATUS
------------------
file
/u01/app/oracle/product/11.2.0/dbhome_1/network/admin/wallet
OPEN
www.killdb.com@column name format a40
www.killdb.com@column masterkeyid_base64 format a60
www.killdb.com@select name,utl_raw.cast_to_varchar2( utl_encode.base64_encode('01'||substr(mkeyid,1,4))) || utl_raw.cast_to_varchar2( utl_encode.base64_encode(substr(mkeyid,5,length(mkeyid)))) masterkeyid_base64 FROM (select t.name, RAWTOHEX(x.mkid) mkeyid from v$tablespace t, x$kcbtek x where t.ts#=x.ts#);
NAME MASTERKEYID_BASE64
------------------- ------------------------------------
SYSTEM AXzox4IR/k+yv2liagPwxyA=
SYSAUX AQAAAAAAAAAAAAAAAAAAAAA=
UNDOTBS1 AQAAAAAAAAAAAAAAAAAAAAA=
USERS AQAAAAAAAAAAAAAAAAAAAAA=
TEMP AQAAAAAAAAAAAAAAAAAAAAA=
www.killdb.com@select utl_raw.cast_to_varchar2( utl_encode.base64_encode('01'||substr(mkeyid,1,4))) || utl_raw.cast_to_varchar2( utl_encode.base64_encode(substr(mkeyid,5,length(mkeyid)))) masterkeyid_base64 FROM (select RAWTOHEX(mkid) mkeyid from x$kcbdbk);
MASTERKEYID_BASE64
------------------------------------------------------------
AXzox4IR/k+yv2liagPwxyA=
[oracle@killdb trace]$ orapki wallet display -wallet /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/wallet
Oracle PKI Tool : Version 11.2.0.4.0 - Production
Copyright (c) 2004, 2013, Oracle and/or its affiliates. All rights reserved.
Enter wallet password: Oracle_
Requested Certificates:
Subject: CN=oracle
User Certificates:
Oracle Secret Store entries:
ORACLE.SECURITY.DB.ENCRYPTION.AXzox4IR/k+yv2liagPwxyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ORACLE.SECURITY.DB.ENCRYPTION.MASTERKEY
ORACLE.SECURITY.TS.ENCRYPTION.BSf3bB90ikAgSJxHC0YxduACAwAAAAAAAAAAAAAAAAAAAAAAAAAA
Trusted Certificates:
我们不难看出,当wallet打开之后,Oracle其实会产生2种key,一种是db的key一种是talespace 级别的key。如下是关于2个x$试图的说明:
x$kcbtek – for tablespaces
x$kcbdbk – the controlfile holds a copy of the master key ID as well.
这2个试图的信息其实都来源于控制文件,这一点我通过10046 trace跟踪可以进行确认,如下是跟踪的结果:
select name,utl_raw.cast_to_varchar2( utl_encode.base64_encode('01'||substr(mkeyid,1,4))) || utl_raw.cast_to_varchar2( utl_encode.base64_encode(substr(mkeyid,5,length(mkeyid)))) masterkeyid_base64 FROM (select t.name, RAWTOHEX(x.mkid) mkeyid from v$tablespace t, x$kcbtek x where t.ts#=x.ts#)
END OF STMT
PARSE #140449938441232:c=7000,e=9686,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=1,plh=1547126948,tim=1476007495117573
EXEC #140449938441232:c=1000,e=33,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=1547126948,tim=1476007495117682
WAIT #140449938441232: nam='SQL*Net message to client' ela= 2 driver id=1650815232 #bytes=1 p3=0 obj#=555 tim=1476007495117700
WAIT #140449938441232: nam='control file sequential read' ela= 8 file#=0 block#=1 blocks=1 obj#=555 tim=1476007495117783
WAIT #140449938441232: nam='control file sequential read' ela= 4 file#=0 block#=16 blocks=1 obj#=555 tim=1476007495117799
WAIT #140449938441232: nam='control file sequential read' ela= 2 file#=0 block#=18 blocks=1 obj#=555 tim=1476007495117806
WAIT #140449938441232: nam='control file sequential read' ela= 2 file#=0 block#=180 blocks=1 obj#=555 tim=1476007495117814
FETCH #140449938441232:c=0,e=898,p=0,cr=0,cu=0,mis=0,r=1,dep=0,og=1,plh=1547126948,tim=1476007495118611
WAIT #140449938441232: nam='SQL*Net message from client' ela= 203 driver id=1650815232 #bytes=1 p3=0 obj#=555 tim=1476007495118877
WAIT #140449938441232: nam='SQL*Net message to client' ela= 1 driver id=1650815232 #bytes=1 p3=0 obj#=555 tim=1476007495118996
FETCH #140449938441232:c=0,e=141,p=0,cr=0,cu=0,mis=0,r=4,dep=0,og=1,plh=1547126948,tim=1476007495119067
STAT #140449938441232 id=1 cnt=5 pid=0 pos=1 obj=0 op='HASH JOIN (cr=0 pr=0 pw=0 time=672 us cost=0 size=66 card=1)'
STAT #140449938441232 id=2 cnt=5 pid=1 pos=1 obj=0 op='FIXED TABLE FULL X$KCCTS (cr=0 pr=0 pw=0 time=78 us cost=0 size=43 card=1)'
STAT #140449938441232 id=3 cnt=5 pid=1 pos=2 obj=0 op='FIXED TABLE FULL X$KCBTEK (cr=0 pr=0 pw=0 time=6 us cost=0 size=2300 card=100)'
WAIT #140449938441232: nam='SQL*Net message from client' ela= 358 driver id=1650815232 #bytes=1 p3=0 obj#=555 tim=1476007495119541
换句话讲,Oracle这里判断key是否匹配只是通过controlfile来判断的。
在其中进行恢复的过程中,进行了多次增量,我们可以基于scn进行全库级别或者文件级别的增量,如下:
run
{
allocate channel d1 type disk;
allocate channel d2 type disk;
allocate channel d3 type disk;
allocate channel d4 type disk;
backup datafile 471,472,473,474,475,476,477,478,479 format '/backup/crmdb_incr_%U.bak';
release channel d1;
release channel d2;
release channel d3;
release channel d4;
}
最后我们通过替换了system文件和重建standby controlfile来完美解决这个问题,如下:
RFS[36]: Selected log 23 for thread 2 sequence 44329 dbid 1035112739 branch 938199971 Fri Jun 30 23:34:36 2017 Archived Log entry 4487 added for thread 2 sequence 44328 ID 0x3ddadfb3 dest 1: Fri Jun 30 23:35:14 2017 Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_30/thread_2_seq_43927.1864.948021793 Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_30/thread_1_seq_31887.1227.948021775 Fri Jun 30 23:36:42 2017 Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_30/thread_2_seq_43928.1957.948021797 Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_30/thread_4_seq_29958.1806.948021775 Media Recovery Log +ARCH/crmdbns/archivelog/2017_06_30/thread_3_seq_32174.1473.948021775 Fri Jun 30 23:37:40 2017 RFS[32]: Selected log 9 for thread 1 sequence 32254 dbid 1035112739 branch 938199971
Related posts: